We propose an asymmetric multi-resolution transformer architecture (denoted MResT) that utilizes the generlization capabilty of large vision-language models together with the robustness of multiple local sensing modalities (wrist-mounted views, vibro-tactile sensors) to perform a range of manipulation tasks particularly more precise and dynamic manipulation tasks.
Real-Time control of precise and dynamic tasks
Real-Time control requires sensing at various spatial and temporal resolutions.Spatial Resolutions
- Low spatial resolutions (e.g. third-person camera view) provide global (coarse) localization.
- High spatial resolutions (e.g. wrist-mounted camera view) provide high accuracy local information thus enabling more precise motions.
Temporal Resolutions
- Low temporal resolutions process quasi-static features from low-resolution sensors such as third-person camera view.
- High temporal resolutions uses dynamic features such as force-torque data which allows the robot to respond to contact events.
Approach Overview
To enable a general multi-task multi-resolution approach we would like to use pretrained vision-language models given their imperessive zero-shot generalization capabilites for image-text grounding. However, large vision-language models can have billions of parameters and thus are hard to scale for real-time control. Further, in practical settings with limited robot training data they are hard to adapt for the downstream task.
Multi-Resolution Architecture
Figure below shows our overall multi-resolution architecture. Our work builds on three critical insights to learn generalizable multi-task policies that allow us to scale to coarse, precise and dynamic manipulation tasks..
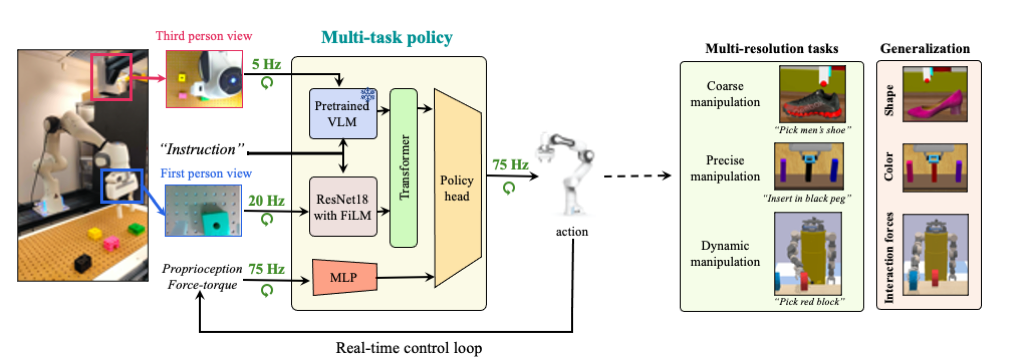
- Generalization via pretraining: We use a large frozen pretrained VLM to enable zero-shot generalization to semantic features (color, shape) as well as grounding to new types of instructions.
- Small networks: To allow real-time control we use small networks with fast inerfecne to process high-spatial resolution sensing modalities (first-person camera view, force-torque data).
- Data Augmentations: To preventsmall networks from affecting the generalization abilities of our large pretrained VLM we use aggressive data augmentations for some high spatial resolution sensors (e.g. first-person camera view). This forces the network to rely on the frozen pretrained VLM for global cotext (thus generalization) while only using the local sensing modality for resolution.
Experiments
We use three differents manipulation domains and real-world experiments to evaluate our proposed approach.
- MT-Coarse: Quasi-static manipulation tasks which only require coarse localization with multiple skills such as pick-place, push.
- MT-Precise: Manipulation tasks that require fine-grained manipulaton e.g. tasks with sub-cm accuracy (inserting small objects). For these tasks we use the set precise tasks from RLBench.
- MT-Dynamic: We use a highly dynamic ballbot (that requires dynamic balancing) for our dynamic tasks.
 Experiment domains used for evaluation.
Experiment domains used for evaluation.
Multi-resolution approach performs well across all different task domains.
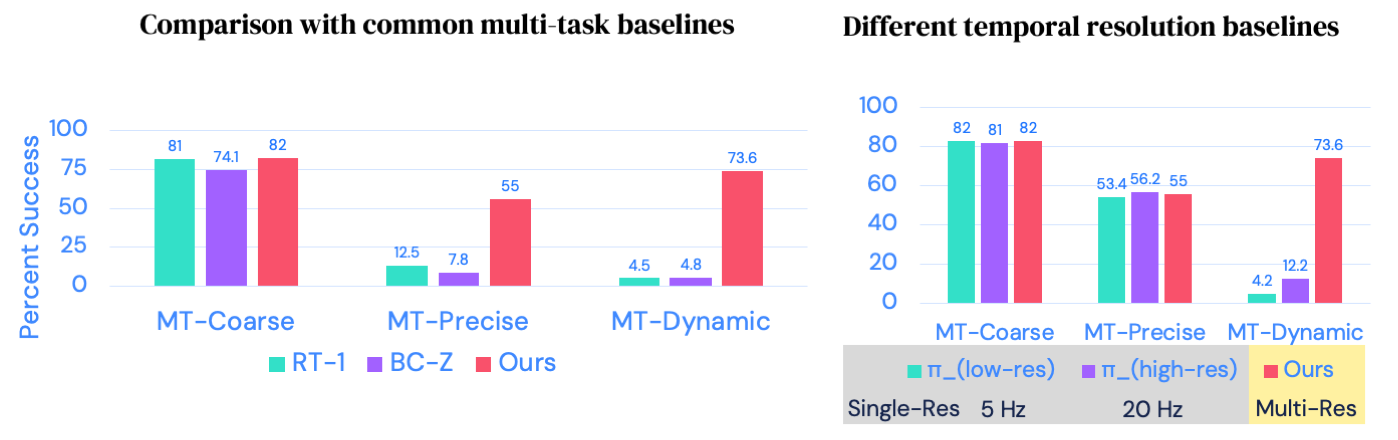
Above figure (Left) compares our multi-resolution approach to common single-resolution multi-task baselines
such as BC-Z and RT-1. While single-resolution approaches do well on coarse manipulation tasks (MT-Coarse), they
perform poorly on precise and dynamic tasks.
For our second result (Right) we show the importance of using a multi-temporal resolution approach.
For this, we use multiple spatial resolutions at fixed temporal resolutions, i.e. low-resolution (5 Hz),
high resolution (20 Hz). While fixed resolution approaches work well for
quasi-static tasks (MT-Coarse and MT-Precise) they fail for our dynamic task where fast-reaction to contact is necessary
for task success.
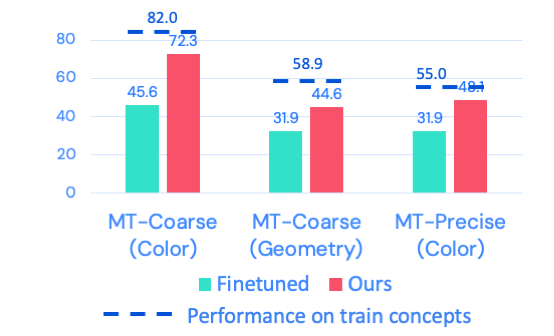
Visual-Semantic generalization to novel concepts.
Figure on the right shows the generalization abilities of our approach. We compare our multi-resolution approach (with frozen VLM) against finetuned VLM. We show the percentage success on novel concepts only as well as training concepts (dotted blue). While there is performance drop on novel concepts (~5-10%), across all different concept variations (i.e. color, geometry) frozen representations outperform finetuned representations when evaluated on novel concepts.